[('단어1', #빈도1), ('단어2', #빈도2), ... , ('단어n', #빈도n)] 이라는 tuple(str, int)-list 두개(input1, inpu2)에서 겹치는 단어(intxn에 추따로 단어만 저장)만 뽑아서 그 빈도수를 더하는 연산이다.
몇달전 초창기에는 전수조사 방식으로 만들었다. 전체 목록을 보며 대조해가면서 조사하라는 구문.
intxn 과 input1, intxn과 input2를 각각 조사해야되다 보니 길이가 엄청나게 길다.
최근에 .index 라는 기능을 찾아내어 이를 썼더니 훨씬 간단해졌다. 실제로 속도가 어마어마하게 빨라졌다. 그래서 처음에 내가 잘못만든줄 알았는데 코드분석 해보니 느릴수밖에 없었겠더라.

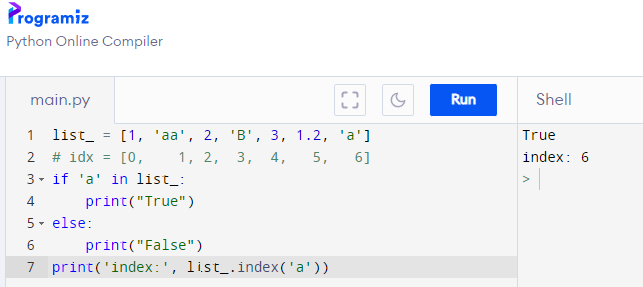
저 index 라는 기능은 특정 행렬에서 어떤 단어의 위치를 반환한다. 어떤 단어가 기존배열에 일치해야만 찾아주므로 걱정없이 쓸 수 있다.
'파이썬(Python) > 간단한 연습' 카테고리의 다른 글
| 판다스 데이터프레임에서 빈 셀은 NaN으로 표기된다. (0) | 2022.11.02 |
|---|---|
| 다중 for loop 의 변수명을 같게 쓰면 안되는 이유: 중간에 바뀐다. (0) | 2022.11.02 |
| time stamp method in Python DeepLearning (0) | 2022.09.27 |
| Kaggle(케글) dataset에 한글제목으로 파일 올리면 이름 깨지는 문제: 해결책 zip 만들어서 올리기 (0) | 2022.09.16 |
| 엑셀 문서의 셀 값이 리스트일 때, 리스트 그대로 파이썬 판다스로 추출하는 방법 (0) | 2022.05.19 |



