for Non-Koreans, directly go to the bottom. There is an English summary. You may translate this article to read, but I think it would not be very helpful, due to incorrectness of automatic-translation between Korean-English.
txt 파일을 with open 으로 불러와 str 로 저장하여, 그 str를 KoNLPy KKMA(꼬꼬마)에 넣고 pos 돌리는데, 일부 텍스트 파일에서만 Decode 에러가 났다. stack overflow 검색으로 이십여 개의 글을 읽어봤으나, 명확한 답은 나오지 않았다.
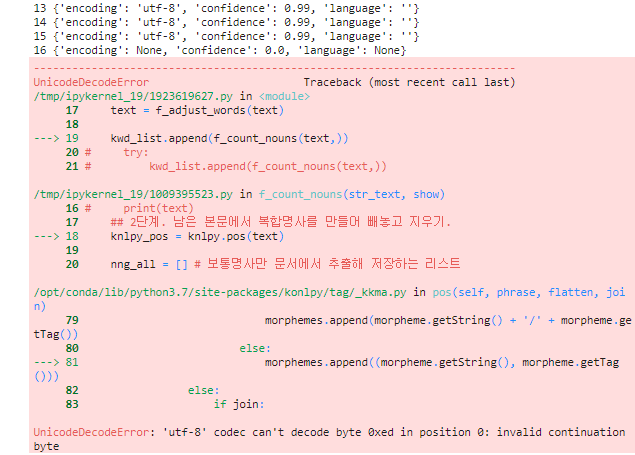
일단 나는 0xed 바이트 invalid continuation byte 문제가 있었다.
아래의 코드에서 특수기호를 붙인 자리는 당신이 알아서 수정하라는 뜻이다. 내가 다른사람 코드읽을때 뭐를 바꾸어야 하는지 감이 안올때가 많아서, 일반가독성을 떨
어뜨리더라도 변수명, 함수명, 옵션 등을 바꾸는 기호를 넣었다. 당연히 실제 코드에서는 특수문자 인식이 안되니 다 지워야 한다.
- ◆variable_name
- ♥function_name
- ▶option_name◀ 자유롭게 바꿀수는 없고, 정해둔 것으로만 바꾸기 된다.
1. with open 에서 조치 >>> 실패
수많은 뺑뺑이를 돌았으나 간단히 요약하면, 각종 코덱과 에러 옵션 조절로는 해결 못했다.
어떤 질의응답(영어)에서 asian language 쓸 때 이런 에러가 잘 생긴다는 댓글을 보고, 그나마 단서를 찾을 수 있었다. 뭔가 언어팩의 결함이겠거니 싶었다.
# 파이썬3 환경이라 utf-8 encode가 기본이다.
with open(◆filename, encoding=▶codec◀, errors=▶option◀) as ◆datafile:
◆str = ◆datafile.read()
# encoding 실패 목록
# utf-8, utf-16,utf-8-sig >>> byte 0xed invalid continuation byte
# unicode_escape >>> □□□□□□□□ 이런식으로 글자 깨져나옴
# cp949, euc-kr >>> \u2013 illegal multibyte sequence 참고로 \u2013은 EN-Dash
# ISO-8859-1, latin-1 >>> ordinal not in range(256)
# errors 실패 목록
# replace, ignore >>> 글자 깨짐
# strict >>> 기본 옵션이라 위의 문제가 나타남.
2. 한줄씩 불러와서 어느 문장이 문제가 되는지 확인하였다.
멀쩡하면 KKMA pos 함수가 작동하여 문제없이 끝나고, 함수를 작동시키지 못하면 문장 위치와 내용을 출력한다.
with open(◆filename, encoding=▶codec◀, errors=▶option◀) as ◆datafile:
◆save_each_line = ◆datafile.readlines() # list. elements are str.
for i in range(len(◆save_each_line)):
line = ◆save_each_line[i].replace('\n','') # 개행 기호만 있으면 에러가 잘나서 지웠다.
try:
check_error = ♥KoNLPy_Kkma_pos(line, 20)
# print(check_error)
except:
print(i, line)
확인해보니 전반적으로 문제인건 아니었고, 특정한 줄 한두군데에서만 에러가 발생했다. 그 예시
22 그래서 문제는 k 가 아니라 𝒜 에 있었습니다. 그래서 문제는 k 가 아니라 𝒜 에 있었습니다.긁어보니까 저 𝒜 가 A와 달랐다. 여기서는 구분이 안가는데, 메모장에 붙여넣어서 보면 A는 1칸짜리인데 𝒜 가 2칸을 먹는다. 그리고 𝒜 가운데에 커서를 둘 수 있었다. 거기에서 반쪽 아무거나 지우면 이렇게 � 로 깨져 나온다.
𝒜 를 아예 빼버리거나 A로 바꾸고 돌리니 아무런 문제가 없었다.
4바이트 문자로 적힌 BCDEF 등에서도 문제가 나타났다.
따라서 encode error 의 유력한 원인은 저런 글자들이라 추측하였고 이를 해결하기 위한 방법을 찾아보았다.
3. byte 로 저장해서 어떤 값인지 확인하고 해결법 찾기
with open(◆filename, 'rb') as ◆datafile:
◆byte_file = ◆datafile.read()
print(◆byte_file)그랬더니 unicode decode error 를 유발하는 글자들은 \xf0\x??\x??\x?? 같은 형식이었다. \xf0 로 시작하였다.
저런 바이트로 시작하는 글자는 4바이트 글자라는 스택오버플로 글(링크#1)을 읽고, 이를 교정하면 되겠다 싶었다.
좋은 방법 하나는 utf-8 대신 utf8mb4 로 인코딩하는 것이다. 그러면 저 4바이트 문자들을 읽어들일 수 있다.
그러나 내가 쓰는 환경에서는 utf8mb4 인코딩을 쓸 수가 없어서 다른 방법이 필요했다.
re 라이브러리를 활용해 3, 4바이트 문자를 바꾸는 스택오버플로 글(링크#2)를 읽고, 베껴썼다.
re_pattern 이라는 걸 정의해서 쓰나보다.
import re
with open(◆filename, 'r', encoding='utf-8', errors='strict') as ◆datafile:
◆original_string_with_mb4letters = ◆datafile.read()
♥re_pattern = re.compile(u'[^\u0000-\uD7FF\uE000-\uFFFF]', re.UNICODE)
◆filtered_string = ♥re_pattern.sub(u'\uFFFD', ◆original_string_with_mb4letters)
◆final = ♥KoNLPy_Kkma_pos(◆filtered_string, 20)
이러니까 오류가 사라졌다. 일단 급한건 해결완료
당신도 입력 str 에 utf-8로 해석되지 않는 글자가 끼어들어갔는지 확인하도록.
4바이트 문자 𝒜가, utf-8로 잘 표기되는 1~2 바이트 문자 A로 바뀐것인지, 아니면 삭제되어 사라져서 KKMA pos 가 동작하는 것인지를 결과물을 보니, 잘 바뀌었다기 보다는 2바이트 문자로 인식되는 어떤 깨진문자표기로 바뀌었다. 내가 작업하는 과정에서는 이것이 Unicode Decode Error 만 안 일으키면 되는 정도라서 일단 넘어간다.
♥re_pattern.sub(u'\uFFFD', ◆original_string_with_mb4letters) 에서 u'\uFFFD' 가 무엇을 의미하는지는 모르겠다.
비슷하나 해결책이 다른 Unicode Decode Error
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xff in position 0: invalid start byte0xff byte 에러는 utf-16 쓰면 해결된다. 아래 링크로 ㄱㄱㄱ.
[Error] UnicodeDecodeError: 'utf-8' codec can't decode byte 0xff in position 0 : invalid start byte
파이참에서 한글이 포함된 파일을 읽으려고 하니, 다음과 같은 오류가 났다. 코드는 다음과 같았다. file = open('파일 경로', 'r', encoding='utf-8') 오류는 다음과 같았다. 에러에서 알 수 있듯이, 인코
soy3on.tistory.com
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xbe in position 34: invalid start byte0xbe 에러는 cp949 쓰면 해결된다.
Only for Non-Koreans
I wrote summary in English. Sorry for inconvenience and lack of details.
Condition
- Python 3.x (I used 3.9.6 or similar version)
- input str variables are asian language mainly (I deal with texts written in Hangul, letters used mostly in Korean)
- working on NLP
Problem
- UnicodeDecodeError : 'utf-8' codec can't decode byte 0xed in position 0: invalid continuation byte
- Neither changing codecs nor ignore/replace encoding errors were not helpful
Solution
'파이썬(Python) > 인코딩' 카테고리의 다른 글
| 인코딩 악의축은 의외로 윈도우 운영체제와 엑셀인듯? (0) | 2022.10.26 |
|---|---|
| UnicodeDecodeError 만드는 바이트값 목록 (0) | 2022.10.10 |
| 한국어 인코딩 과정에서 나오는 주요 Unicode Decode Error 목록 (0) | 2022.10.09 |
| 유니코드 그룹 표(Unicode groups table in EN & KR) (0) | 2022.10.07 |

