내가 이 문제로 골머리를 좀 앓는다.
나 포함 Unicode Decode Error 와 다투는 많은 이들을 위해 도움이 되었으면 좋겠다.
1. 들어가기에 앞서,
- position number를 이해한다.
byte_data = b'\x00\x01\x02\x03\x04 ... \0xFF' 라는 예시를 들겠다.
인코딩 오류를 볼때 아래의 개념을 쓴다.
in position 0 == 0번째 위치 == 바이트값 \x00
in position 1 == 1번째 위치 == 바이트값 \x01
in position 2 == 2번째 위치 == 바이트값 \x01
in position 255 == 255번째 위치 == 바이트값 \xFF
실제 텍스트 데이터는 이보다 복잡하게 나올 것이다만.
- 바이트, 인코딩, 유니코드 사이의 관계
핵심만 정리하면 아래처럼 나온다.
이 문단이 길어서, 접은글로 정리
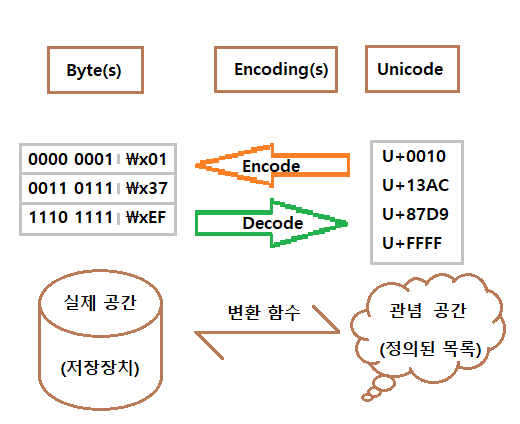
그러나 실제로 유니코드 공간이 존재하여 그걸 쓰는 게 아니라, 저장장치에 부호로 저장하여 두었다가, 원하는 인코딩들로 해석하여, 유니코드 공간에서 정의한 문자로 보여주는 방식이다.
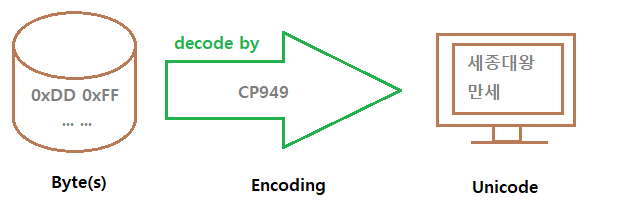
실제로는 (인코딩#1, 할당된저장공간#1)의 세트로 존재해야 하며, 아래처럼 동작한다.
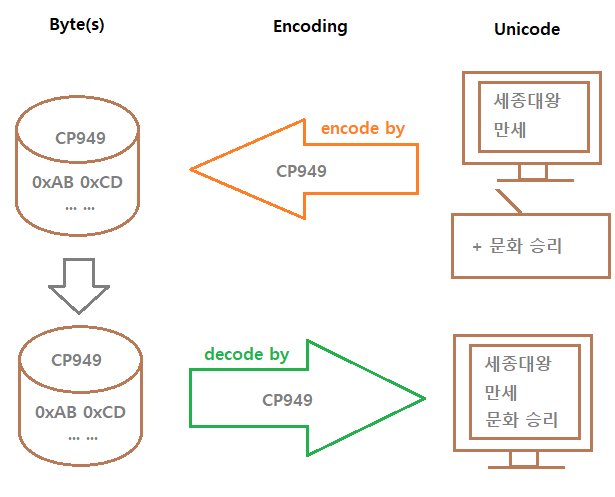
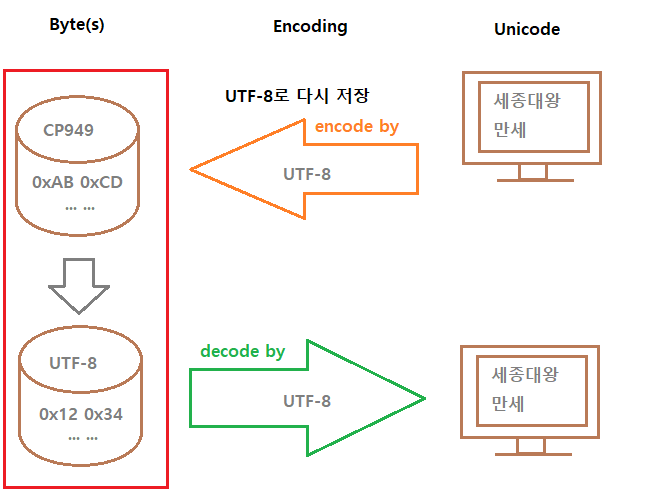
인코딩을 바꿔주면 아래처럼 바뀐다.
실제로 유니코드가 할당된 구획과 그 이름이 궁금하면, 내가 정리한 표를 보시오. 아래 글 -> 구글드라이브 스프레드시트
유니코드 그룹 표(Unicode groups table in EN & KR)
인코딩 관련 조치에 이어서, 이번엔 utf-8 이 어느어느 영역에 어떤 것을 할당했는지 확인해 보았다. 일부는 번역이 되어 있으나, 전부 다 되어있지는 않아서 직접 다 메웠다. 노가다라 몇시간 걸
believe-google-god.tistory.com
- 기타 헷갈릴 만한 몇가지
- ₩xFF == \xFF == 0xFF == hex(FF) 인데 컴퓨터에 집어넣어서 돌릴때 일반숫자 0 과 16진수 표기값인걸 구분하려고 저렇게 쓴다.
- 1바이트 == 8비트 == 2진수 0000 0000 ~ 1111 1111 == \x00 ~ \xFF
2. Unicode Decode Error Types and Solution
이제 본격적인 에러 유형과 해법을 알아보자.
사실 해법은 별거없다. 다른 인코딩으로 바꿔가면서 돌려본다.
(한국어는 utf-8, cp949, utf-16-le 요 순서로 돌려보고 안되면 마이너 인코딩 찾아서 쓴다.)
(영어권은 utf-8, latin-1 == ISO-8859-1, cp1252, utf-16-le 이 순서로 돌려보고 안되면 마이너 인코딩 찾기.)
Truncated Data
입력 단위보다 작은 비트/바이트를 집어넣어, 일부가 잘렸을 때 뜬다.
- 문자 하나를 표현하는데 16비트(2바이트)가 필요한 utf-16에서, 3바이트(24bit)가 들어가서 생기는 문제이다. 마지막 글자에 8비트만 들어갔다. (코드는 스택오버플로에서 발췌)
s1 = b'\xe2\x80\x99'
print(s1.decode("utf-16-le"))
>>>
UnicodeDecodeError: 'utf-16-le' codec can't decode byte 0x99 in position 2: truncated data
ordinal not in range
인코딩 가능한 범위를 넘어선 입력 바이트값이 들어갔을때 뜬다.
대부분 인코딩 가능범위가 좁은, ASCII 와 Latin-1 등을 쓰면 이런 문제가 잘 뜬다.
- ASCII 인코딩은 0x00 부터 0x7F 까지만 입력바이트 인식하고
- Latin-1 인코딩은 0x00 부터 0xFF 까지만 입력바이트 인식한다.
(ASCII는 여기 링크에서 발췌. Latin-1은 내 경험담으로 대충 복원)
UnicodeDecodeError: 'ascii' codec can't decode byte 0xbe in position 0: ordinal not in range(128)
UnicodeDecodeError: 'latin-1' codec can't decode byte 0xbe in position 0: ordinal not in range(256)invalid start byte
바이트_묶음의 첫번째 바이트가 유효하지 않을 때
- 예를 들어, utf-8은 바이트_묶음이 0xFF(1111 1111) 로 시작하면, 해당 값으로 시작할 수 없는 규칙을 쓰기 때문에 오류가 뜬다.
s1 = b'\x00\x11\xff\xe2\x80'
print(s1.decode("utf-8"))
>>>
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xff in position 2: invalid start byte
# \x00 과 \x11 은 잘 decode 하였다.invalid continuation byte
여러바이트_묶음을 decode 돌리는데 첫 바이트가 아닌 바이트가 유효하지 않을 때
- 바이트묶음의 모든 비트는 0 또는 1로 잘 설정되었을 때를 전제로 한다. 비트 일부가 존재하지 않으면 바로아래의 unexpected end of data를 띄운다.
- 파이썬에서는 해당 바이트묶음의 시작 위치와 시작값을 에러 문구로 되돌려준다. 문제가 되는 중간 바이트를 말하지 않는다는 점에 유의할 것.
- utf-8 에서는 나머지 바이트는 반드시 (bin) 10xx xxxx 꼴이어야 하므로, 이와 일치하는 0x80 ~ 0xFF 값만을 쓸 수 있다. 따라서 (bin) 0xxx xxxx 로 들어오는 0x00 ~0x7F 사이의 값을 중간바이트로 보내면 오류가 난다. (이 값들은 첫 바이트에 들어가면 decode되어 에러나지 않는다.)
s0 = '이'
b = s0.encode('utf-8') # == b'\xec\x9d\xb4'
b1 = b'\xec\x9d\xb4\xec\x1d\xb4'
s1 = b1.decode('utf-8')
print(s1)
>>>
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xec in position 3: invalid continuation byte
## 해설: 16진수를 2진수로 바꿔서 바이트를 확인해보면 이해된다.
\xec\x9d\xb4
= e c 9 d b 4
= 1110 1100, 1001 1101, 1011 0100
\xec\x1d\xb4
= e c 1 d b 4
= 1110 1100, 0001 1101, 1011 0100
# 2번째 바이트 이후로는 반드시 10@@ @@@@ 여야 하는데, 0001 1101 이므로 문제가 생긴 것이다.unexpected end of data
바이트묶음으로 인식하려는데, 바이트묶음의 마지막 바이트의 일부 비트가 아예 없을 때
- 바이트 단위로 부르기 때문에 중간 비트가 손실되어도 1바이트씩 불러서 우연히 invalid continuation byte 가 안뜰수도 있다.
s0 = '이'
b = s0.encode('utf-8') # == b'\xec\x9d\xb4'
b1 = b'\xec\x9d'
s1 = b1.decode('utf-8')
print(s1)
>>>
UnicodeDecodeError: 'utf-8' codec can't decode bytes in position 0-1: unexpected end of data
## 해설
## 시작이 \xec라서 3바이트로 인식하는데, b1에는 2바이트만 존재하고 마지막 바이트가 아예 없다.
illegal multibyte sequence
문자가 할당되지 않은 값(undefined character)을 입력했을 때
- 주로 cp949 등 Non UTF 인코딩에서 볼 수 있다.
b1 = b'\xF8\x64'
s1 = b1.decode('cp949')
print(s1)
>>>
UnicodeDecodeError: 'cp949' codec can't decode byte 0xf8 in position 0: illegal multibyte sequence문자 집합 위키(링크)에 가보면 검정색으로 칠해둔 값인 것을 알 수 있다. 행값(0~3)+열값(1)으로 2바이트 만든다.
- 분홍: (Defined) 출력 불가능한 문자
- 노랑: (Defined) ASCII와 차이가 있는 부분
- 연두: (Undefined) 사용자 정의 영역
- 회색: (Defined) 비어 있음
- 검정: (Undefined) 사용되지 않음
이정도 알면 충분히 오류를 수정할 수 있을 것이다.
물론 이거 아는 시간에 그저 인코딩 바꿔서 넣어보는게 효과적ㅋ.
'파이썬(Python) > 인코딩' 카테고리의 다른 글
| 인코딩 악의축은 의외로 윈도우 운영체제와 엑셀인듯? (0) | 2022.10.26 |
|---|---|
| UnicodeDecodeError 만드는 바이트값 목록 (0) | 2022.10.10 |
| 유니코드 그룹 표(Unicode groups table in EN & KR) (0) | 2022.10.07 |
| Unicode Decode Error : 'utf-8' codec can't decode byte 0xed in position 0: invalid continuation byte 문제를, 해결할 수도 있는 한가지 방법 (0) | 2022.09.16 |

